Deploy this version
- Docker
- Pip
docker run
-e STORE_MODEL_IN_DB=True
-p 4000:4000
ghcr.io/berriai/litellm:main-v1.67.4-stable
pip install litellm==1.67.4.post1
Key Highlights
- Improved User Management: This release enables search and filtering across users, keys, teams, and models.
- Responses API Load Balancing: Route requests across provider regions and ensure session continuity.
- UI Session Logs: Group several requests to LiteLLM into a session.
Improved User Management
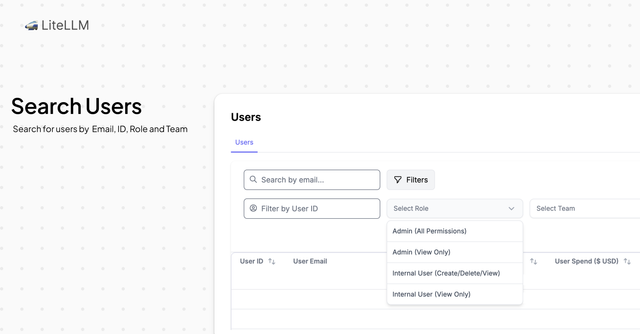
This release makes it easier to manage users and keys on LiteLLM. You can now search and filter across users, keys, teams, and models, and control user settings more easily.
New features include:
- Search for users by email, ID, role, or team.
- See all of a user's models, teams, and keys in one place.
- Change user roles and model access right from the Users Tab.
These changes help you spend less time on user setup and management on LiteLLM.
Responses API Load Balancing

This release introduces load balancing for the Responses API, allowing you to route requests across provider regions and ensure session continuity. It works as follows:
- If a
previous_response_idis provided, LiteLLM will route the request to the original deployment that generated the prior response — ensuring session continuity. - If no
previous_response_idis provided, LiteLLM will load-balance requests across your available deployments.
UI Session Logs
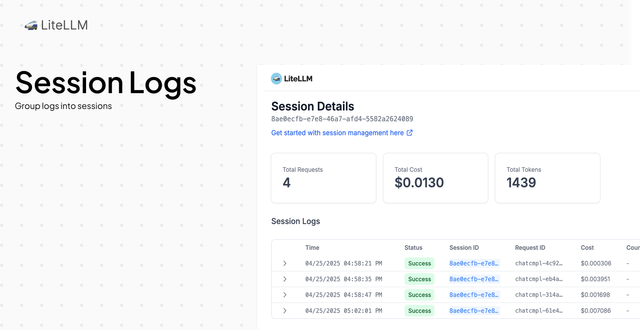
This release allow you to group requests to LiteLLM proxy into a session. If you specify a litellm_session_id in your request LiteLLM will automatically group all logs in the same session. This allows you to easily track usage and request content per session.
New Models / Updated Models
- OpenAI
- Added
gpt-image-1cost tracking Get Started - Bug fix: added cost tracking for gpt-image-1 when quality is unspecified PR
- Added
- Azure
- Fixed timestamp granularities passing to whisper in Azure Get Started
- Added azure/gpt-image-1 pricing Get Started, PR
- Added cost tracking for
azure/computer-use-preview,azure/gpt-4o-audio-preview-2024-12-17,azure/gpt-4o-mini-audio-preview-2024-12-17PR
- Bedrock
- Added support for all compatible Bedrock parameters when model="arn:.." (Bedrock application inference profile models) Get started, PR
- Fixed wrong system prompt transformation PR
- VertexAI / Google AI Studio
- Allow setting
budget_tokens=0forgemini-2.5-flashGet Started,PR - Ensure returned
usageincludes thinking token usage PR - Added cost tracking for
gemini-2.5-pro-preview-03-25PR
- Allow setting
- Cohere
- Added support for cohere command-a-03-2025 Get Started, PR
- SageMaker
- Added support for max_completion_tokens parameter Get Started, PR
- Responses API
- Added support for GET and DELETE operations -
/v1/responses/{response_id}Get Started - Added session management support for non-OpenAI models PR
- Added routing affinity to maintain model consistency within sessions Get Started, PR
- Added support for GET and DELETE operations -
Spend Tracking Improvements
- Bug Fix: Fixed spend tracking bug, ensuring default litellm params aren't modified in memory PR
- Deprecation Dates: Added deprecation dates for Azure, VertexAI models PR
Management Endpoints / UI
Users
Filtering and Searching:
- Filter users by user_id, role, team, sso_id
- Search users by email
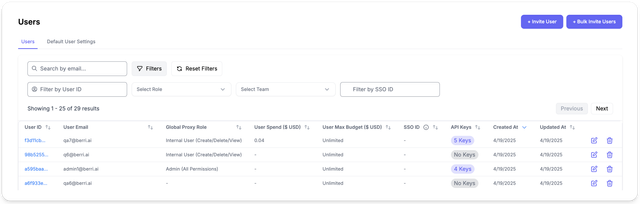
User Info Panel: Added a new user information pane PR
- View teams, keys, models associated with User
- Edit user role, model permissions
Teams
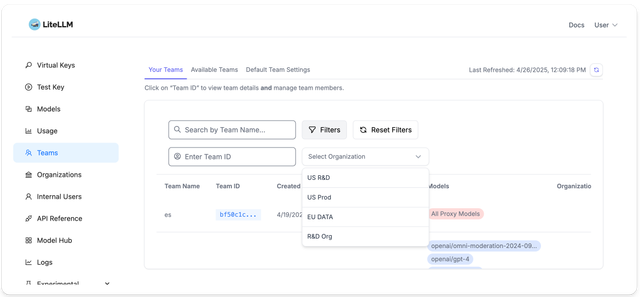
Keys
- Key Management:
UI Logs Page
- Session Logs: Added UI Session Logs Get Started
UI Authentication & Security
- Required Authentication: Authentication now required for all dashboard pages PR
- SSO Fixes: Fixed SSO user login invalid token error PR
- [BETA] Encrypted Tokens: Moved UI to encrypted token usage PR
- Token Expiry: Support token refresh by re-routing to login page (fixes issue where expired token would show a blank page) PR
UI General fixes
- Fixed UI Flicker: Addressed UI flickering issues in Dashboard PR
- Improved Terminology: Better loading and no-data states on Keys and Tools pages PR
- Azure Model Support: Fixed editing Azure public model names and changing model names after creation PR
- Team Model Selector: Bug fix for team model selection PR
Logging / Guardrail Integrations
- Datadog:
- Fixed Datadog LLM observability logging Get Started, PR
- Prometheus / Grafana:
- Enable datasource selection on LiteLLM Grafana Template Get Started, PR
- AgentOps:
- Added AgentOps Integration Get Started, PR
- Arize:
- Added missing attributes for Arize & Phoenix Integration Get Started, PR
General Proxy Improvements
- Caching: Fixed caching to account for
thinkingorreasoning_effortwhen calculating cache key PR - Model Groups: Fixed handling for cases where user sets model_group inside model_info PR
- Passthrough Endpoints: Ensured
PassthroughStandardLoggingPayloadis logged with method, URL, request/response body PR - Fix SQL Injection: Fixed potential SQL injection vulnerability in spend_management_endpoints.py PR
Helm
- Fixed serviceAccountName on migration job PR
Full Changelog
The complete list of changes can be found in the GitHub release notes.